October 14, 2024/2 min read
Vision Transformers
An in-depth introduction to Vision Transformers and their potential to revolutionize the field of computer vision.
Table of Contents
- Introduction
- Architecture
- Image Tokenization
- Transformer Encoder
- Training
- Applications
Introduction
The Vision Transformers (ViTs) leverage the transformer[2] architecture to process visual data. For natural language, transformers have shown to be very effective in processing sequential data using self-attention mechanisms.
The key idea behind ViTs is to treat an image as a sequence of pixels, rather than as a 2D grid. This is achieved by flattening the image into a 1D sequence and then using a series of self-attention mechanisms to process the data.
Architecture
Most of the architecture of ViTs is similar to the transformer architecture used in natural language processing. The main difference is the tokenization process applied to the input data. In natural language processing, the tokenization process is applied to the input text to generate a sequence of tokens generally sub-word units.
Image Tokenization
Now, the question that arises is in the case of images, what should be the tokens? We can't use the same tokenization process as for text, since images are 2D and text is 1D.
One way to tokenize images is to break them down into a smaller grid of non-overlapping patches. Each patch is then treated as a token.
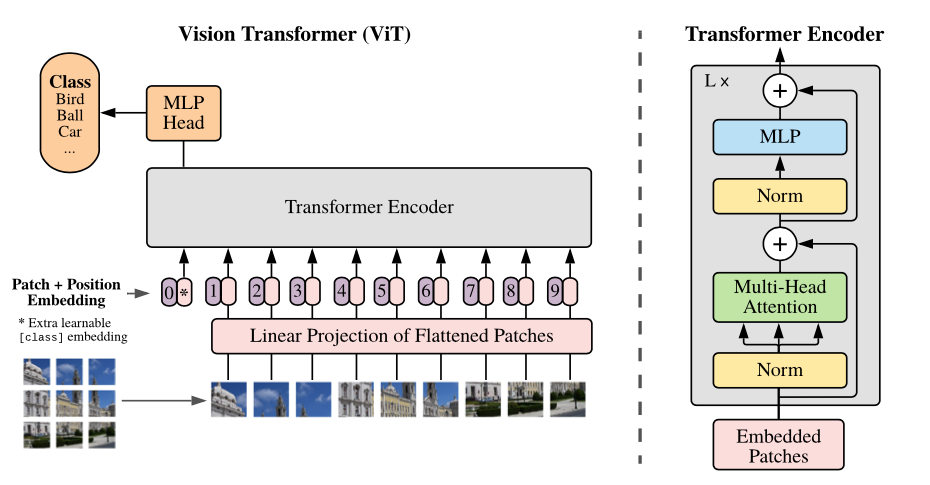
Position Embeddings are added to the patches to preserve the position information. Since the patches are flattened into a 1D sequence, the position embeddings are also 1D. The position embeddings are learned during training.
Transformer Encoder
The encoder is a series of transformer layers/blocks. Just like in the transformer architecture, the layers are composed of a multi-head self-attention mechanism and a feed-forward network.
Training
The ViTs are trained using a combination of supervised and self-supervised learning. The supervised learning is used to train the model to classify images into different categories. The self-supervised learning is used to train the model to predict the position of the patches in the image.
references
- Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv:2010.11929
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention is All You Need. arXiv:1706.03762