March 20, 2024/4 min read
Transformers: Attention is All You Need
Transformers have become the building blocks of many state-of-the-art AI models. This post provides a detailed explanation of the Transformer architecture which was introduced in the paper 'Attention is All You Need'
Table of Contents
- Introduction
- Pre-transformer Sequence Models: RNNs
- The Advent of Transformers
- Common Transformer Types
- Encoder-Decoder Transformer
- Decoder-Only Transformer
- Encoder-Only Transformer
- Transformer Architecture
- Attention Layers
- Feedforward Layers
1. Introduction
Transformers are a neural network architecture that use self-attention to process sequential data in parallel. This allows the model to focus on different parts of the input independently, efficiently managing long-range dependencies. Composed of layers of self-attention and feed-forward networks called transformer blocks, it excels in tasks such as machine translation and text generation by simultaneously capturing relationships across the entire sequence.
2. Pre-transformer Sequence Models: RNNs
Recurrent Neural Networks (RNNs) were the primarily used for sequence-based tasks before the introduction of the Transformer architecture. However, these models had their limitations. RNNs suffered from the vanishing gradient problem and were slow to train. CNNs were computationally expensive and struggled with capturing long-range dependencies.
3. The Advent of Transformers
The Transformer architecture was introduced by Vaswani et al in the 2017 paper "Attention is All You Need,"[1]. Though attention mechanism were used in sequence models before as well, their work introduced a robust architectural framework that stood the test of time. It employs a self-attention mechanism that independently assesses the relevance of each input token, facilitating more effective predictions. The core design remains largely unchanged, underscoring its enduring impact on AI research and development.
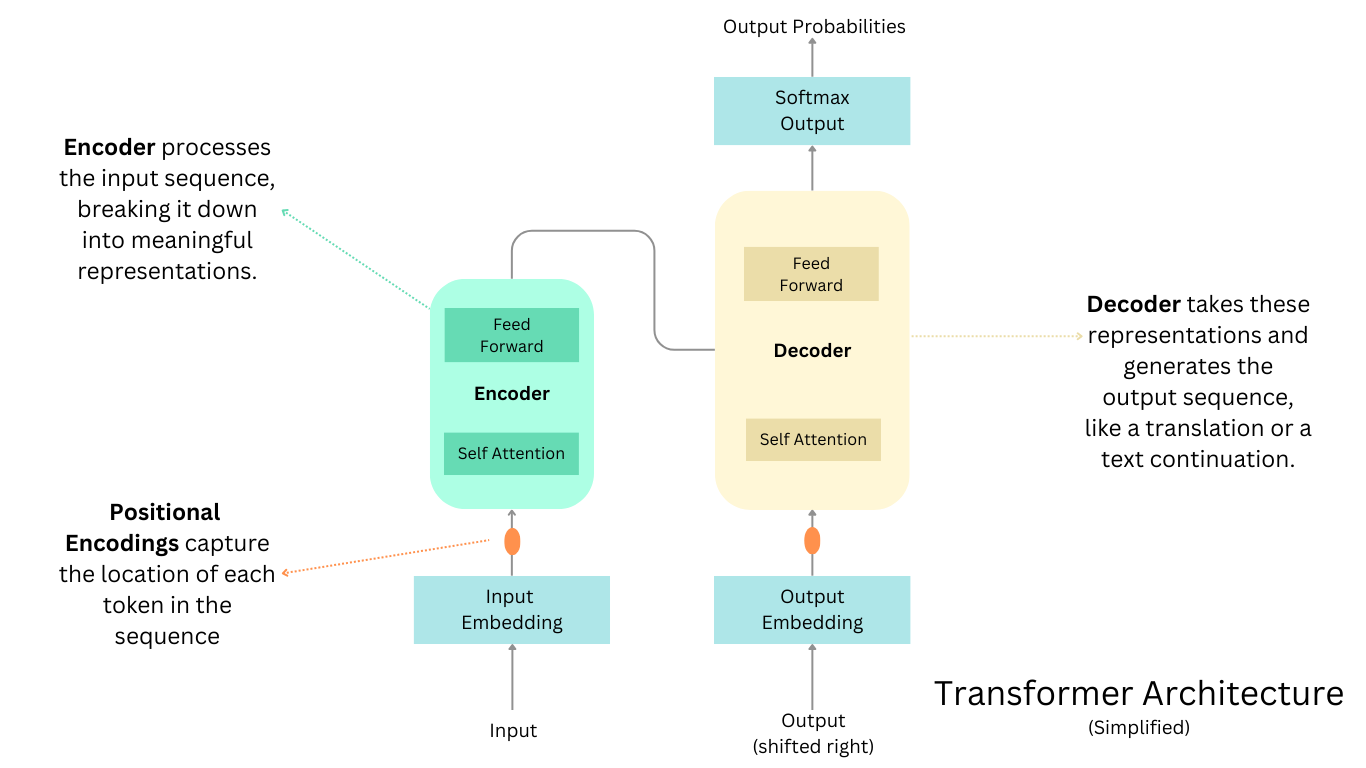
Figure 1: Simplified Transformer Architecture with Encoder and Decoder.
4. Common Transformer Architectures
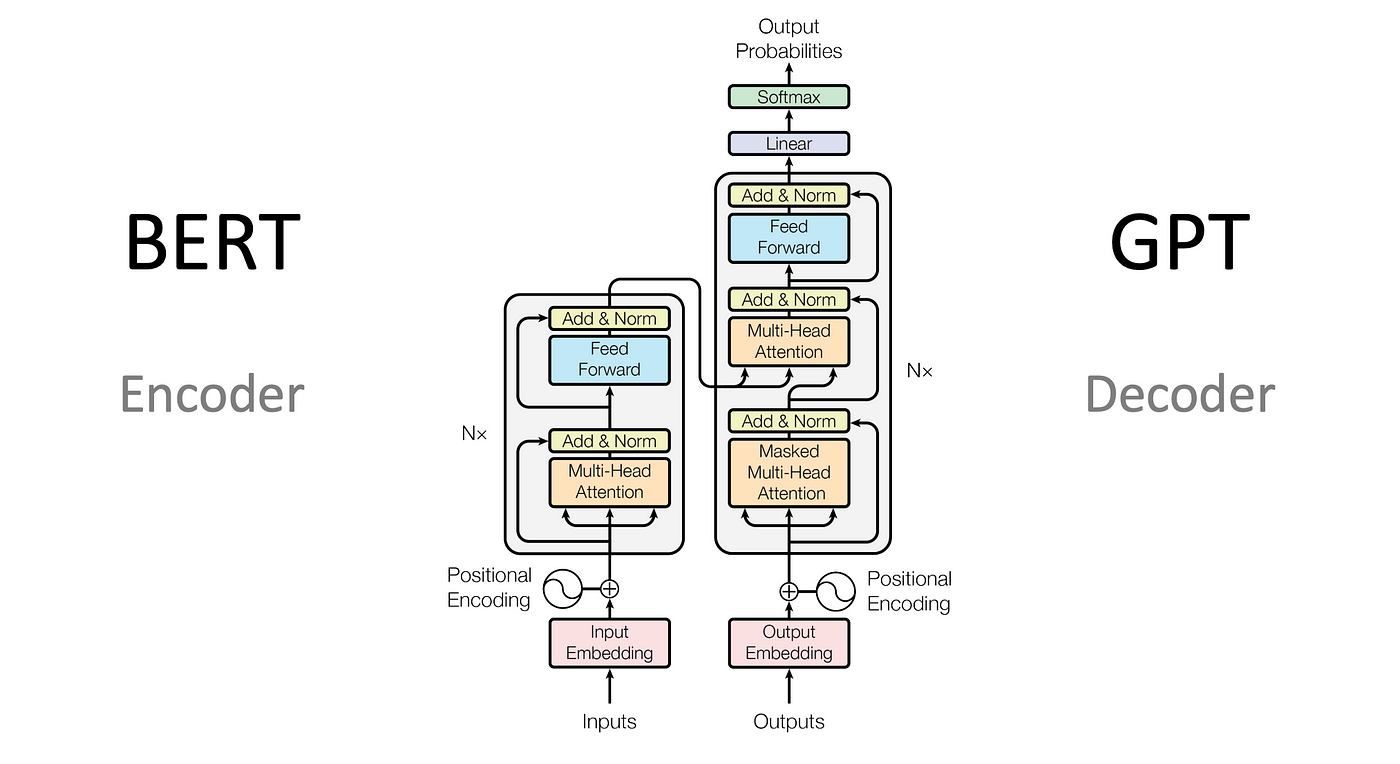
Figure 2: The left unit of the original transformer architecture is the encoder, and models like BERT use only the encoder part. The right unit is the decoder, and models like GPT use only the decoder part
Transformers today are widely used in a variety of tasks, including machine translation, text generation, question answering, and more. The transformer architecture is adapated to various configurations depending on the task at hand. The common configurations include:

Figure 3: Common Transformer Configurations. 1. Encoder-Decoder Transformer - eg: the original transformer, 2. Decoder-Only Transformer - eg: GPTs, 3. Encoder-Only Transformer - eg: BERT.
4.1. Encoder-Decoder Transformer
Used for sequence-to-sequence tasks like machine translation. Models such as the original Transformer, BART, T5, etc. are based on this configuration
4.2. Decoder-Only Transformer
Used for tasks like text generation or language modeling. Models such as GPT-3, Mixtral, Gemma, etc. are based on this configuration
4.3. Encoder-Only Transformer
Used for tasks like text classification. Models such as BERT, RoBERTa, DistilBERT, etc. are based on this configuration
5. Transformer Architecture
The Original Transformer introduced in Vaswani et al [1] had two main components - the Encoder and the Decoder.
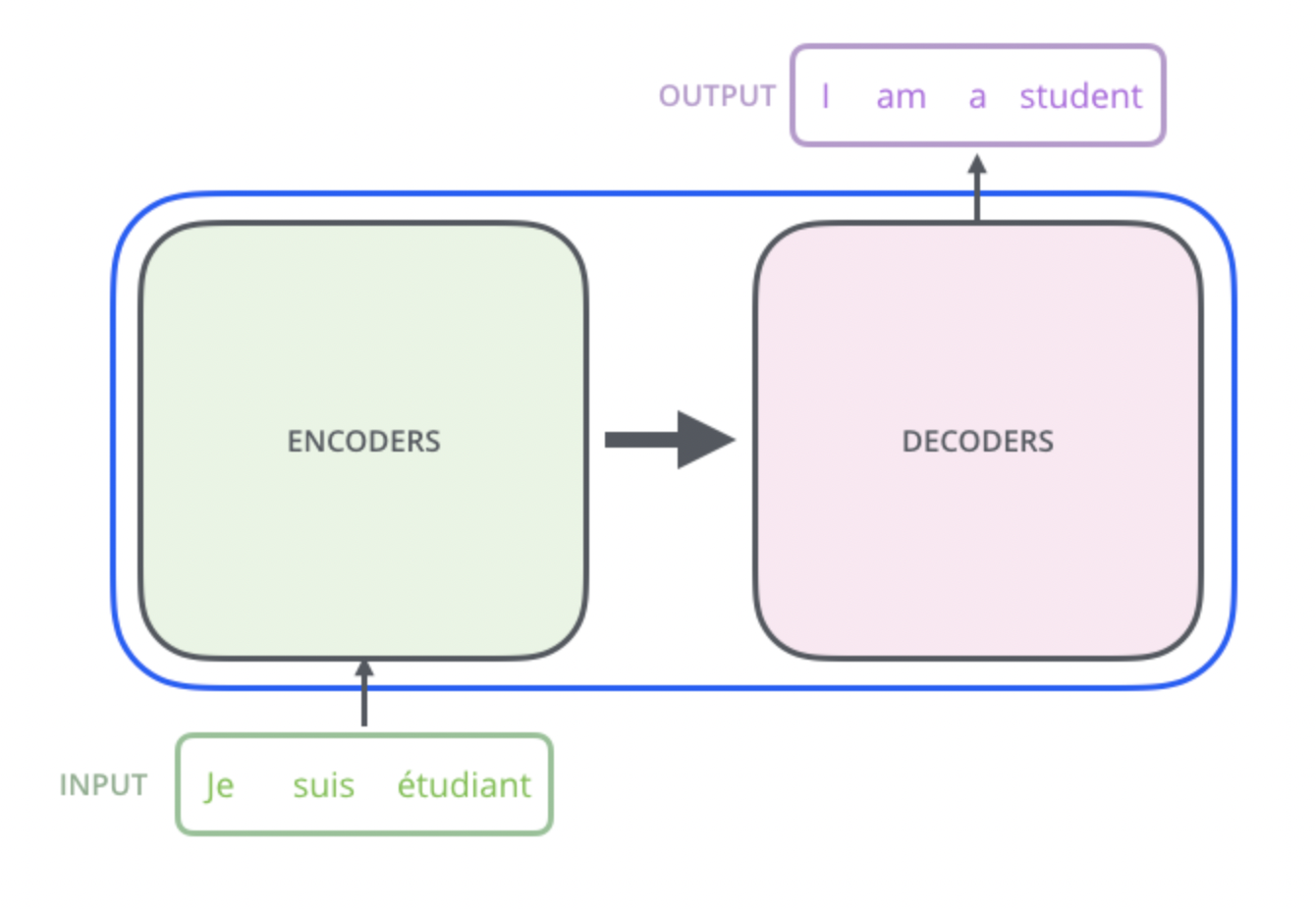
Figure 4: Components of the Transformer Architecture - Encoder (green) and Decoder (red). Encoder receives the input and decoders generates the output.
The encoder receives the input sequence and processes it to create a representation that captures the information in the input sequence. This is then passed to the decoder, which generates the output sequence based.
Even this is a simplification of the Transformer architecture. Each of the encoder and decoder are composed of smaller building blocks called Transformer Blocks. These blocks are stacked on top of each other to form the complete encoder and decoder. In the original Transformer, the encoder and decoder each had 6 Blocks.
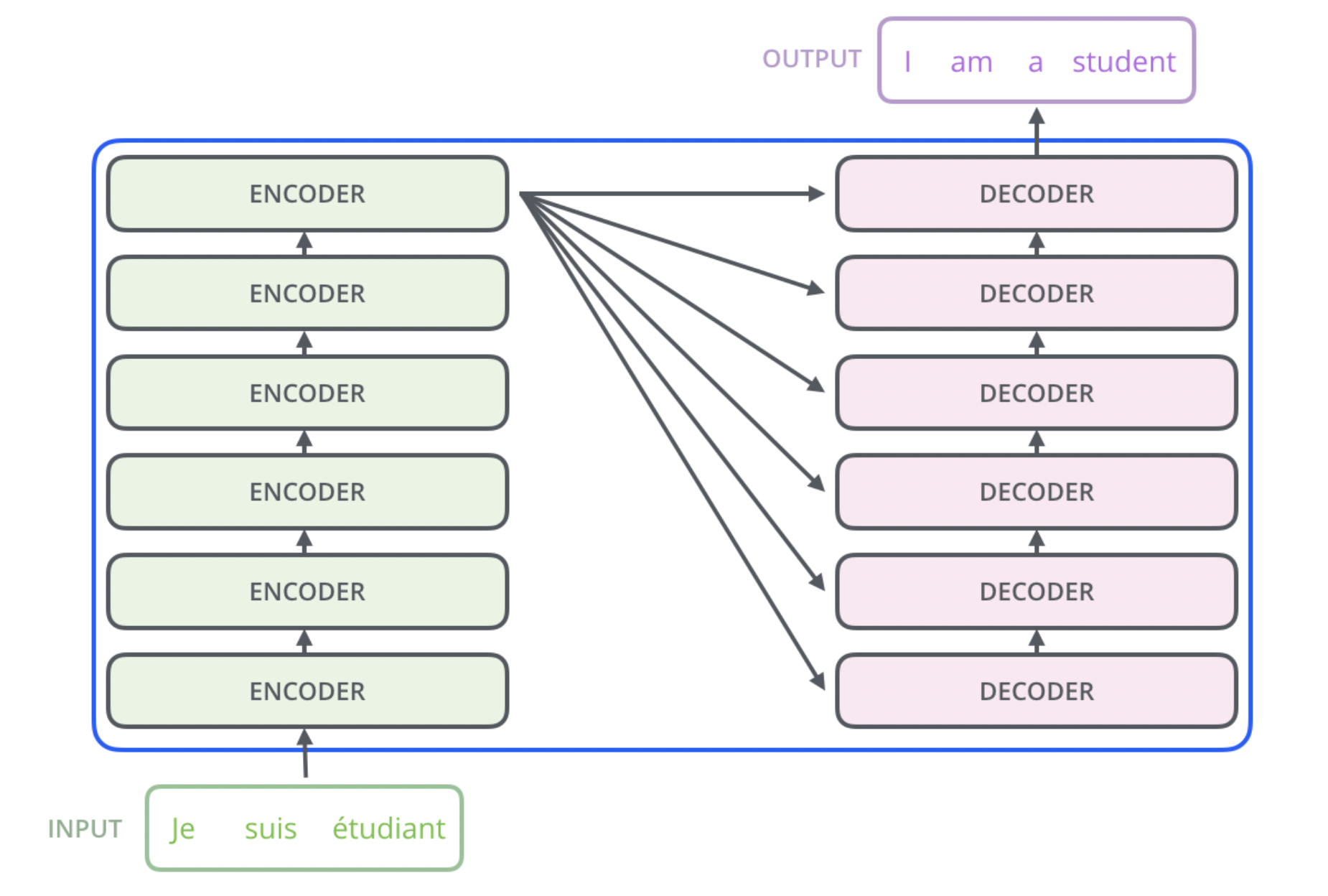
Figure 5: Transformer Blocks - The building blocks of the Transformer architecture. Each encoder and decoder had 6 of these blocks in the original Transformer.
Now, let's dive deeper into workings of one of the Transformers Block and understand it in detail. Each Transformer block whether a block in encoder or decoder consists of the following components:
5.1 Attention Layers
The attention mechanism is the core component of the Transformer architecture. It allows the model to focus on different parts of the input sequence when making predictions. The attention mechanism ensures that the model can capture long-range dependencies and weigh the importance of different input tokens.
5.2 Feedforward Layers
The feedforward layers in the Transformer architecture are used to transform the output of the attention layers into a format that is suitable for the final prediction. The feedforward layers consist of a number of linear transformations with an activation function in between them.
references
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention is All You Need. arXiv:1706.03762