April 11, 2024/4 min read
How Stable Diffusion works
A deep dive into the architecture and inner workings of the revolutionary generative model, Stable Diffusion developed by Stability AI
Stable Diffusion has completely revolutionized the field of generative models. It is a generative model that is capable of generating high-quality images. It is based on the concept of diffusion models and has been developed by Stability AI. In this article, we will take a deep dive into the architecture and inner workings of Stable Diffusion.
This post is divided into the following sections:
- Architecture of Stable Diffusion
- 1.1. Diffusion Models
- 1.2. Latent Diffusion Models
- Components of Stable Diffusion
- Training
1. Latent Diffusion Models [LDM]
The research paper released for Stable Diffusion by Stability AI was named "High-Quality Image Generation with Latent Diffusion Models"[1]. Let's focus on the two key concepts that this title emphasizes, "High-Quality Image" and "Latent Diffusion Models".
1.1 Diffusion Models
Diffusion Models follow an iterative process where a noise tensor is refined over multiple steps to generate an image. The process is known as Diffusion Process. The diffusion process is a stochastic process that starts with a noise tensor and iteratively refines it to generate an image. Now, while this iterative approach was good for generating small-sized images, it was computationally expensive and difficult to scale to high-quality images.
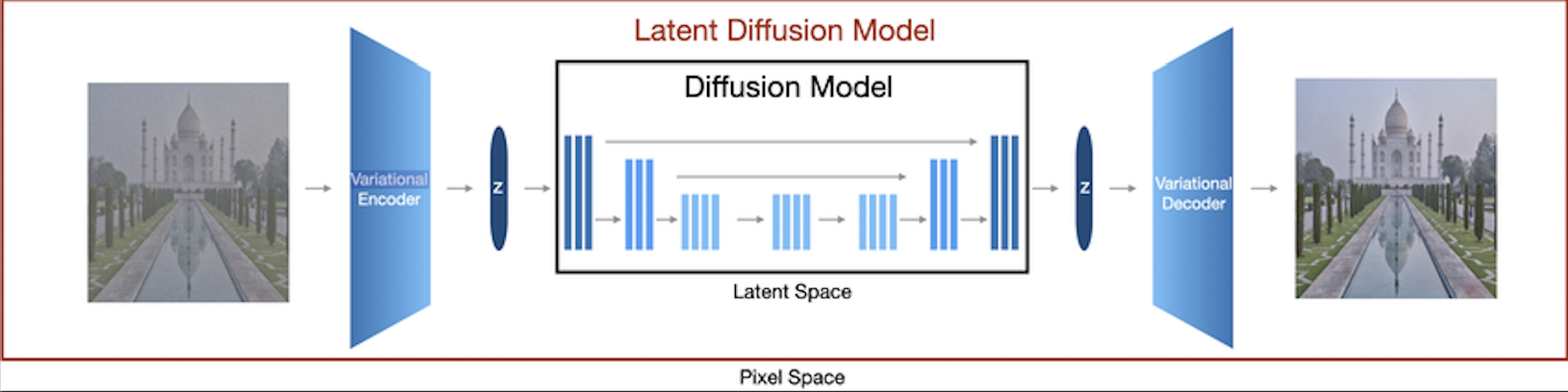
1.2 Latent Diffusion Models
Introduced in Stable Diffusion paper[1], Latent Diffusion Models (LDMs) are a class of generative models that are build on the concept of Diffusion Models (DMs). LDMs address the limitations of DMs by a neat little trick.
LDM Trick: Diffusion Process in Latent Space instead of Pixel Space
Instead of refining the noise tensor in pixel space, LDMs refine the noise tensor in a learned latent space. This latent space is a low-dimensional representation of the images that captures the underlying structure of the data. So, the entire diffusion process takes place in this latent space, making it more efficient and scalable. Refer to the image above to how the diffusion step is performed in the latent space.
While pixel-based DMs were computationally expensive and difficult to train, LDMs offer a more efficient and scalable alternative. As opposted to DMs, here the diffusion process takes place in a learned Latent Space. This latent space is a low-dimensional representation of the images that captures the underlying structure of the data.
2. Components of Stable Diffusion
- Text Encoder: Converts textual descriptions into embeddings
- Diffusion Model: Generates images by iteratively refining a noise tensor
- Decoder: Converts the noise tensor into an image
1.1. Text Encoder
The text encoder in Stable Diffusion plays a crucial role in converting textual descriptions into a format that the model can use to generate images. Stable Diffusion 1 uses the OpenAI's CLIP as its text encoder.
We have a separate post on how CLIP works which can be read here CLIP: Briding Vision and Language. However, here's a concise explanation of how it works.
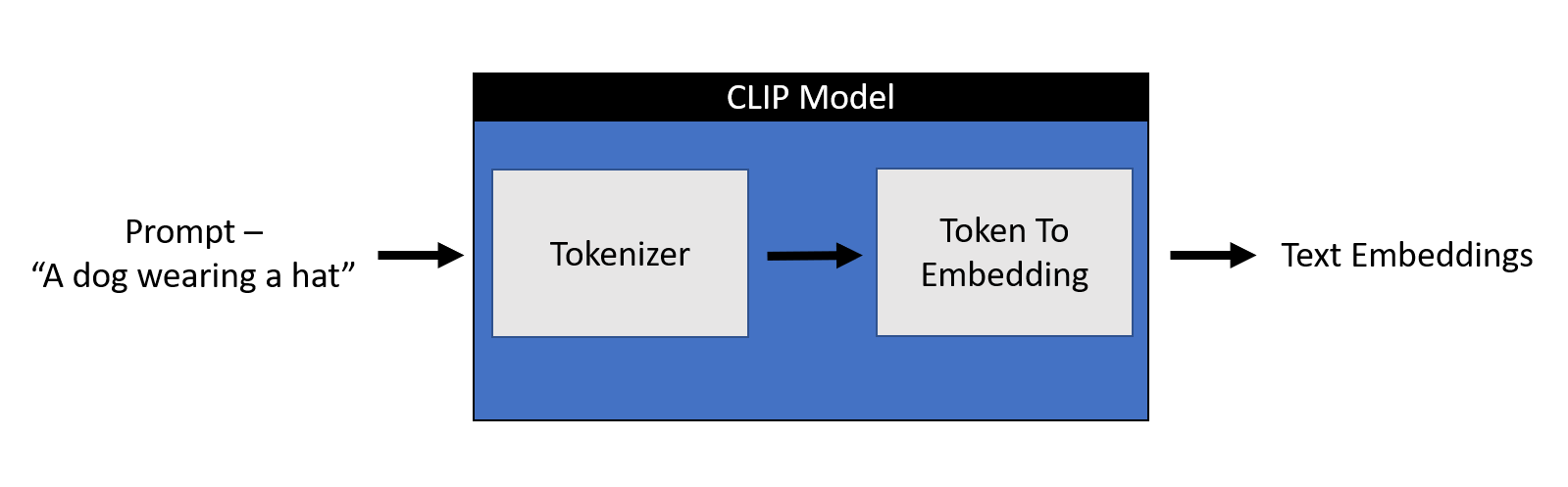
Input Text: The process begins when the model receives a piece of text describing the image to be generated. For example, "a cat sitting on a sunny windowsill."
Tokenization: The text encoder first breaks down the input text into smaller units called tokens. Tokens can be words, parts of words, or even punctuation marks. In our example, the tokens might be
["a", "cat", "sitting", "on", "a", "sunny", "windowsill"]
The input text cannot be greater than 77 tokens which is the context length of the underlying CLIP model.
OpenAI's CLIP model has a vocabulary of 49,408 tokens.
Embedding: Each token is then mapped to a high-dimensional vector, known as an embedding. These embeddings capture the semantic meaning of the tokens. The text encoder has been trained on a large dataset to ensure that similar words have similar embeddings.
Contextualization: The text encoder processes the sequence of embeddings to account for the context of each word in the sentence. This is typically done using a transformer architecture, which allows the model to understand the relationships between words in the sentence. For example, it understands that "sunny" is describing the "windowsill" and not the "cat."
Output: The output of the text encoder is a contextualized representation of the input text. This representation captures the meaning of the entire sentence in a format that can be used by the rest of the Stable Diffusion model to generate the corresponding image.
In summary, the text encoder in Stable Diffusion transforms textual descriptions into a high-dimensional, contextualized representation that serves as the foundation for image generation.
2. Training
references
- Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer. High Resolution Image Synthesis with Latent Diffusion Models. arXiv:2112.10752
- Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. arXiv:2103.00020
- Ali Razavi, Aaron van den Oord, Oriol Vinyals. Generating Diverse High-Fidelity Images with VQ-VAE-2. arXiv:1906.00446