March 21, 2024/4 min read
BERT: Bidirectional Encoder Representations from Transformers
Understand how the widely used BERT model works and its architecture is related to the Transformer model. Also, learn how BERT is pre-trained and fine-tuned for various NLP tasks
Table of Contents
- Introduction
- BERT Architecture
- Training
- Pre-training
- Fine-tuning
- Conclusion
Introduction
BERT (Bidirectional Encoder Representations from Transformers) has revolutionized the field of Natural Language Processing (NLP). It's a powerful model that forms the backbone of many state-of-the-art language understanding systems. In this post, we'll explore what BERT is, how it works, and why it's so important.
If you're new to Transformers, don't worry! While some familiarity helps, we'll cover the essentials as we go. If you want a deeper dive into Transformers, check out my previous post on the topic.
BERT Architecture
BERT was introduced in 2018, just a year after the groundbreaking Transformer model was published. To understand BERT, let's start by looking at its origins in the Transformer architecture.
From Transformer to BERT
The original Transformer model, designed for tasks like machine translation, consists of two main parts: an encoder and a decoder.
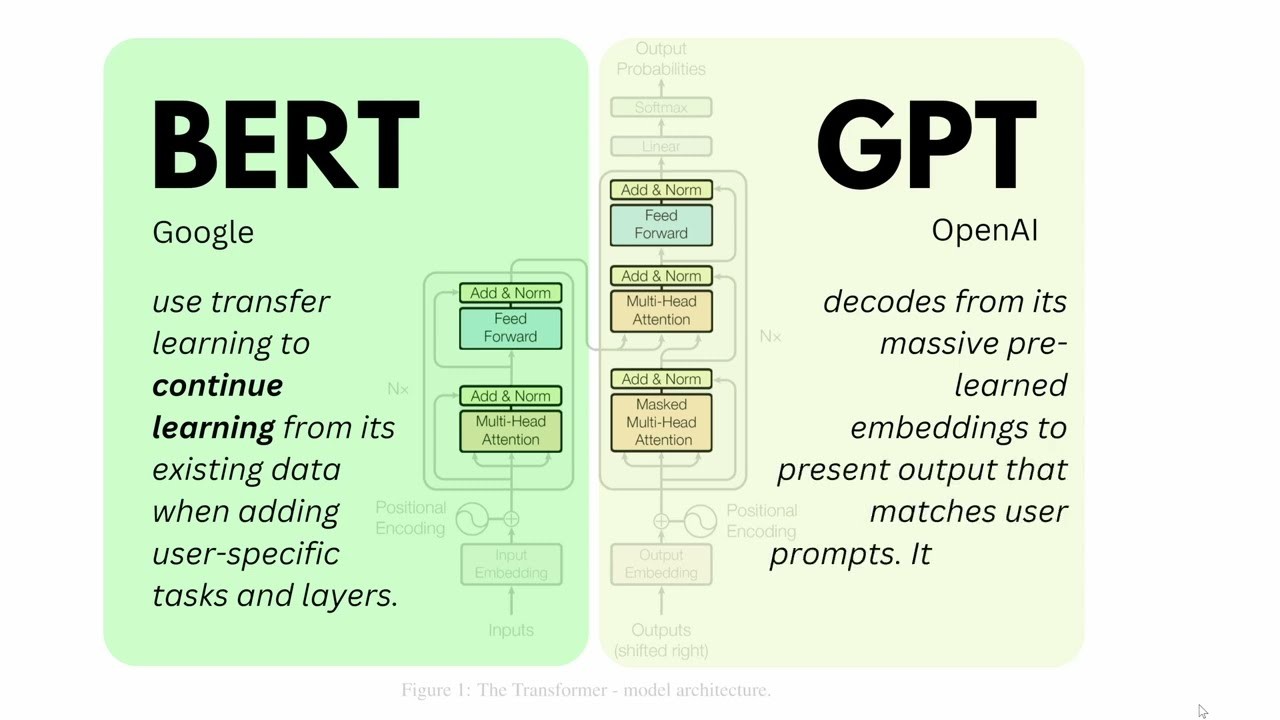
Figure 1: The Transformer Model consists of an encoder and a decoder. BERT is based on the encoder part, while models like GPT use the decoder architecture.
Now, imagine that we break down the Transformer model into two separate models: an encoder and a decoder. The encoder model (BERT like model) is used to capture the context of words into a contextualized word representation, which can then be used for various NLP tasks. While the decoder model (GPT like model) is used to generate a sequence of tokens, conditioned on the input sequence. With this in mind, the acronym BERT which stands for Bidirectional Encoder Representations from Transformers, would make more sense.
What Does "Bidirectional" Mean?
A key feature of BERT is its bidirectional nature. But what does that mean?

Figure 2: Bidirectional means that BERT considers words both before and after a given word to understand its meaning in context.
When we read a sentence, we naturally consider the entire context to understand each word. BERT mimics this by looking at words both before and after (bidirectional) the target word. This bidirectional approach allows BERT to capture richer context compared to models that only look at previous words.
BERT's Structure
At its core, BERT is a stack of Transformer encoder layers. Each layer processes the input sequence, refining the understanding of each word based on its context. The final output of the model are bidirectional contextualized embeddings, one for each input token.
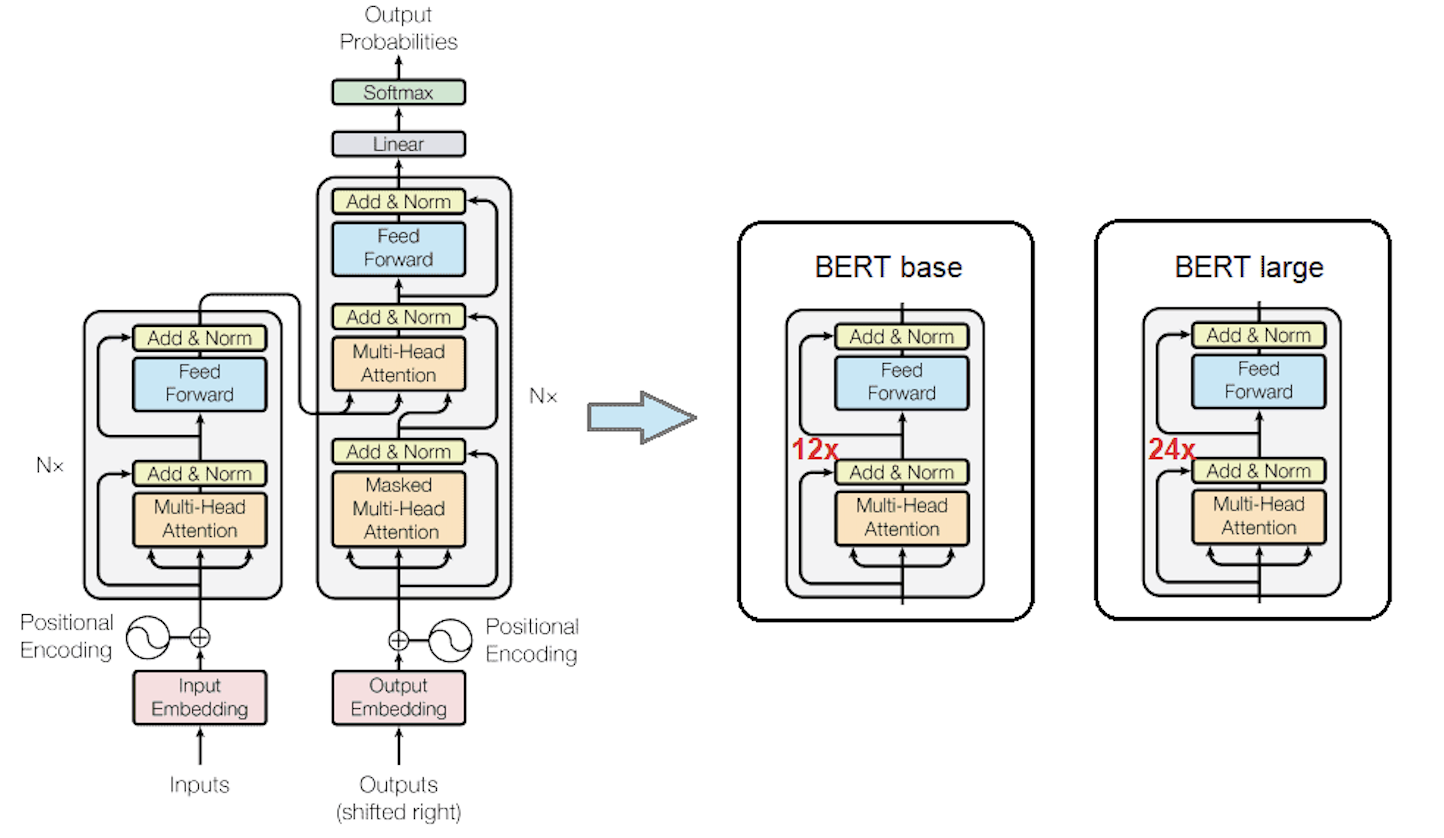
Figure 3: BERT's architecture consists of multiple Transformer encoder layers. BERTBASE has 12 layers, while BERTLARGE has 24 layers for even more processing power.
BERT takes a sequence of tokens (words or parts of words) as input. These tokens are first converted into vectors (embeddings) and then processed through the layers. The output is a sequence of vectors that represent each input token, now enriched with contextual information.
BERT has two versions: BERTBASE and BERTLARGE. BERTBASE has 12 layers and 110M parameters, while BERTLARGE has 24 layers and 340M parameters.
Training
BERT's training process is what gives it its power and flexibility. It happens in two main phases: pre-training and fine-tuning.
Pre-training
In the pre-training phase, BERT learns from a massive amount of text data without any specific task in mind. It's like giving BERT a crash course in language understanding. This phase uses two clever training objectives:
-
Masked Language Modeling (MLM): Some words in the input are randomly masked, and BERT has to predict what they are. This forces the model to use context from both directions to make its predictions.
-
Next Sentence Prediction (NSP): BERT is given pairs of sentences and has to predict whether the second sentence naturally follows the first. This helps BERT understand relationships between sentences.
These tasks help BERT develop a deep understanding of language structure and context.
Fine-tuning
After pre-training, BERT is like a language expert that can be specialized for specific tasks. This is where fine-tuning comes in.
During fine-tuning, we take the pre-trained BERT model and add a small layer on top tailored to a specific task. We then train this modified model on labeled data for that task. This could be:
- Question answering
- Sentiment analysis
- Text classification
- And many more!
The beauty of this approach is that BERT can be quickly adapted to a wide range of NLP tasks, often achieving state-of-the-art results with relatively little task-specific training data.
Conclusion
BERT's bidirectional approach and clever training process have made it a game-changer in NLP. By creating rich, context-aware representations of language, BERT has opened up new possibilities in language understanding and processing.
As NLP continues to evolve, BERT remains a foundational model, inspiring new architectures and approaches. Whether you're a researcher, developer, or just curious about AI, understanding BERT is a great step towards grasping the exciting world of modern NLP.
references
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention is All You Need. arXiv:1706.03762