April 16, 2024/4 min read
RoPE: Rotary Positional Embedding
An in-depth look at RoPE, a novel positional encoding method that uses sinusoidal embeddings to capture the relative positions of tokens in a sequence.
LLMs (Large Language Models), like any other ML models can only work with numbers. So, to understand large chunks of text, LLMs need to convert the text into numbers. This is done using a process called Tokenization in Large Language Models, where each word or subword is assigned an index from a fixed vocabulary.
Now, the corresponding token embeddings, which enscapsulates the semantic meaning of that word/sub-word, are passed as input to encoder of the Transformer models. But these token embeddings however do not capture the position of the token in the sequence. Now, this would be fine if the sequence of words did not matter in a language, but unfortunately it does.
But why do Transformers need positional encodings? Doesn't SelfAttention capture positional information?
Transformers, unlike recurrent neural networks (RNNs) or long short-term memory networks (LSTMs), do not have an inherent mechanism to process sequential data in order. Instead, they process all tokens in the input sequence simultaneously, which is why they are so efficient in parallel computation.
The SelfAttention mechanism in Transformers does allow each token to attend to every other token in the sequence, enabling the model to capture relationships between tokens.
However, without positional embeddings, the model would treat sequences such as
Adam ate an appleandApple ate an Adamas identical, because the attention mechanism would produce the same output for both sequences.
Now, this is where Positional embeddings come in. They encode the position of each token, providing the model with information about the order of the tokens which is crucial for understanding the implied meaning.
Absolute Positional representations
In the original Transformer model, (Vaswani et al., 2017), sinusoidal positional embeddings were used to capture the position of tokens in the sequence. These positional embeddings are added to the token embeddings before feeding them to the model. This is static and does not change during training. It works well when there are not many tokens in the sequence, but it does not generalize well to longer sequences.
Positional embeddings
However, as the space of language models has evolved, so has the need for better positional embeddings. Trained positional embeddings, were introduced by the BERT model (Devlin et al., 2018). These embeddings are learned during training, and are able to capture the position of tokens in the sequence more effectively than the original sinusoidal embeddings.
These learned positional embeddings are added to the token embeddings before feeding them to the model. Since, these embeddings are learned similar to token embeddings, they make the model computationally more expensive.
import torch.nn as nn
class Embeddings(nn.Module):
def __init__(self, vocab_size, max_len, embed_dim):
super(Embeddings, self).__init__()
# Initialize token and positional embeddings
self.token_embeddings = nn.Embedding(vocab_size, embed_dim)
self.positional_embeddings = nn.Embedding(max_len, embed_dim)
def forward(self, x):
# Get token embeddings
token_embeds = self.token_embeddings(x)
# Get positional embeddings
pos = torch.arange(0, x.size(1)).unsqueeze(0)
pos_embeds = self.positional_embeddings(pos)
# Add token and positional embeddings
return token_embeds + pos_embedsThe above code snippet shows how the token embeddings and positional embeddings are added together. Here both both token and positional embeddings are of the same dimensionality and are learned during training.
GPT2 also uses learned 768 dimensional positional embeddings (same size as token embeddings) to capture the position of tokens in the sequence.
RoPE: Rotary Positional Embedding
In 2021, Rotary embeddings, were introduced in the paper "RoFormer: Enhanced Transformer with Rotary Position Embedding". Instead of using separate positional embeddings, rotary embeddings apply a rotation operation to the token embeddings based on their positions. This rotation is a function of the position, and it effectively mixes the positional information with the token embeddings. The key advantage is that this approach preserves the inner product of the embeddings, which is important for the attention mechanism in transformers.
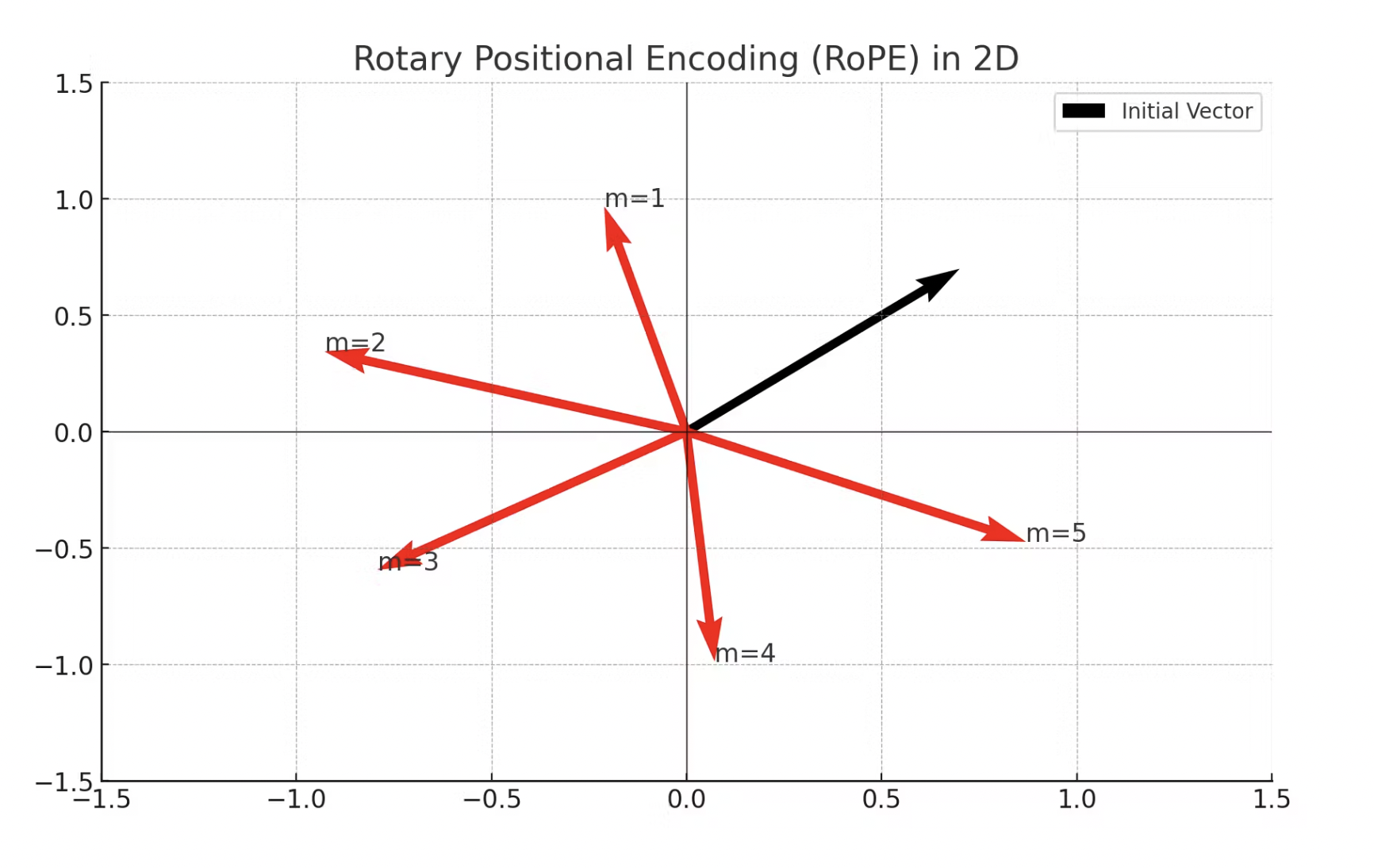
Two main advantages of using RoPE over learned positional embeddings:
-
Interpretability: As you can see in the above image, with regards to interpretability, the rotation operation in rotary embeddings has a clear geometric interpretation, which can make the model's use of positional information more transparent.
-
Computational Efficiency: More efficient in terms of memory and computation, as they do not require additional parameters like positional embeddings. This can be particularly advantageous for long sequences. Also, at training time, this eliminates the need to learn the positional embeddings.
Open-source SOTA models such as Llama, GPT-Neo, Llama2, Mistral 7B and Mixtral 8x7B use RoPE for positional encoding.
references
- Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, Yunfeng Liu. RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv:2104.09864
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention is All You Need. arXiv:1706.03762
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805