October 11, 2024/4 min read
Paligemma: Versatile VLM - Vision Language Models
Deep-dive into Paligemma Google's innovative vision language model. Learn about its architecture, capabilities, and potential applications in AI and machine learning.
Table of Contents
- Introduction
- What are VLMs - Vision Language Model?
- Architecture and Technical Details
- Applications and Use Cases
- Comparison with Other VLMs
- Conclusion
Introduction: Meet Paligemma! 👋
Paligemma is an exciting new addition to the world of artificial intelligence, developed by the brilliant minds at Google. This open-source family of Vision Language Models (VLMs) has been making waves in the AI community due to its impressive performance across a wide range of tasks. In this post, we'll dive deep into what makes Paligemma special and why it's capturing the attention of researchers and developers alike.
What's VLM? 🤔
Okay, before we go gaga over Paligemma, let's break down what a Vision Language Model (VLM) actually is:
Imagine an AI model could not only understand text but also see and understand images. That's basically what a VLM does! It's AI that can process and understand both images and text. Unlike traditional Large Langugage Models (LLMs) that work solely with text. A VLM can:
- Analyze images and understand their content
- Read and comprehend text
- Connect visual information with textual descriptions
- Generate text based on visual inputs
- Answer questions about images
This multimodal capability allows VLMs to provide rich, contextual understanding of problems that involve both visual and textual elements.
Paligemma's Architecture
So, how does Paligemma process visual and textual data? Now, we know that LMs break down text into tokens, and then process them. VLMs do the same with images and text. They break down the image into smaller parts (called patches) and the text into tokens.
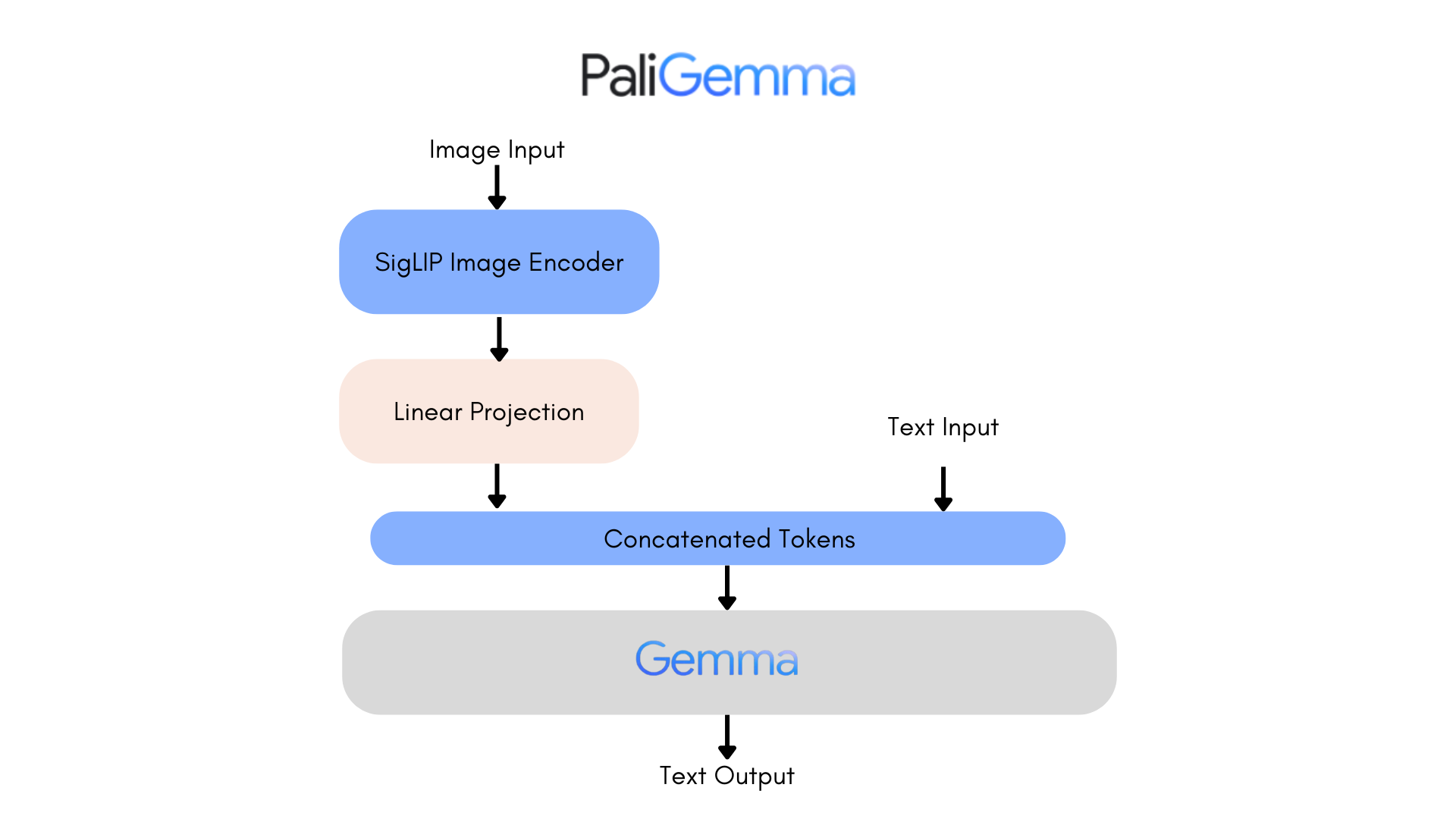
Figure 1: Paligemma Architecture. The image is broken down into smaller patches using SigLIP model. Then a linear projection is applied to bring the patch tokens into a common embedding space. The text tokens are then concatenated with the image patch tokens. The concatenated sequence of tokens is then processed using the Gemma language model.
Both the image patch tokens and the text tokens are brought into a common embedding space concatenated together so that the language model can process them together.
Paligemma's architecture combines two key components:
-
Vision Encoder (SigLIP-So400m): Based on the SigLIP (Simple Grouped Learning of Image and Text Pairs) model, which efficiently processes visual information.
-
Language Model (Gemma-2B): Utilizes the Gemma-2B language model, known for its strong text generation and understanding capabilities.
This combination allows Paligemma to effectively bridge the gap between visual and textual data processing.
Tokenizer
Since the language mode used is Gemma, so Paligemma uses the Gemma tokenizer with a vocabulary of 256,000 tokens. But to handle images the original vocabulary is extended with 1024 entries that represent cooridinates in normalized image-space(<loc0000>...<loc1023>) and with another 128 entries (<seg000>...<seg127>) that are codewords used by a lightweight referring-expression segmentation vector-quantized variational autoencoder.
Applications and Use Cases
The potential applications for Paligemma are vast and exciting:
- Image captioning: Automatically generating descriptive captions for images.
- Visual question answering: Answering questions about the content of images.
- Text-to-image generation: Creating images based on textual descriptions.
- Image search and retrieval: Improving the accuracy of image search engines.
- Accessibility tools: Assisting visually impaired users by describing images.
- Content moderation: Identifying inappropriate or harmful visual content.
- Medical imaging analysis: Assisting in the interpretation of medical images.
Comparison with Other VLMs
While Paligemma is impressive, it's important to understand how it stacks up against other VLMs:
- CLIP: OpenAI's model known for its zero-shot learning capabilities.
- DALL-E: Specializes in text-to-image generation.
- ViLBERT: Another popular VLM used for various vision-language tasks.
Paligemma distinguishes itself through its open-source nature and focus on efficient fine-tuning for specific tasks.
Conclusion
Paligemma represents an exciting step forward in the field of vision language models. Its open-source nature, strong performance, and versatility make it a valuable tool for researchers and developers working on multimodal AI applications. As the field continues to evolve, we can expect to see Paligemma and similar models playing an increasingly important role in bridging the gap between visual and textual understanding in artificial intelligence.
Google has released 3 different types of Paligemma models:
- PT checkpoints - Pre-trained models that can be fine-tuned for any downstream task.
- Mix checkpoints - Pre-trained models fine-tuned to a mixture of tasks. They are suitable for general-purpose inference.
- FT checkpoints - Fine-tuned models for specialised tasks.
The models support three different image resolutions:
- 224x224
- 448x448
- 896x896
and three different precision:
- bfloat16
- float16
- float32
Stay tuned for more developments in this fascinating area of AI research!
references
- Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, Thomas Unterthiner, Daniel Keysers, Skanda Koppula, Fangyu Liu, Adam Grycner, Alexey Gritsenko, Neil Houlsby, Manoj Kumar, Keran Rong, Julian Eisenschlos, Rishabh Kabra, Matthias Bauer, Matko Bošnjak, Xi Chen, Matthias Minderer, Paul Voigtlaender, Ioana Bica, Ivana Balazevic, Joan Puigcerver, Pinelopi Papalampidi, Olivier Henaff, Xi Xiong, Radu Soricut, Jeremiah Harmsen, Xiaohua Zhai. Paligemma: A versatile 3B VLM for transfer. arXiv:2407.07726
- Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer. SigLIP: Sigmoid Loss for Language Image Pre-Training. arXiv:2303.15343
- Gemma Team. Gemma: Open Models Based on Gemini Research and Technology. arXiv:2403.08295