July 26, 2025/19 min read
Normalization Techniques in Transformer-Based LLMs: LayerNorm, RMSNorm, and Beyond
Deep dive into the evolution of normalization techniques in transformer-based LLMs, from the trusty LayerNorm to newer variants like RMSNorm, and even experimental tweaks.
Large Language Models (LLMs) are massive Transformer networks, and keeping them stable during training is like keeping a tall stack of dishes balanced – a little wobble in one layer can cascade to disaster in layers above. To prevent this, deep models rely on normalization techniques that keep activations in check, ensuring each layer’s outputs have a consistent scale (and sometimes zero mean).
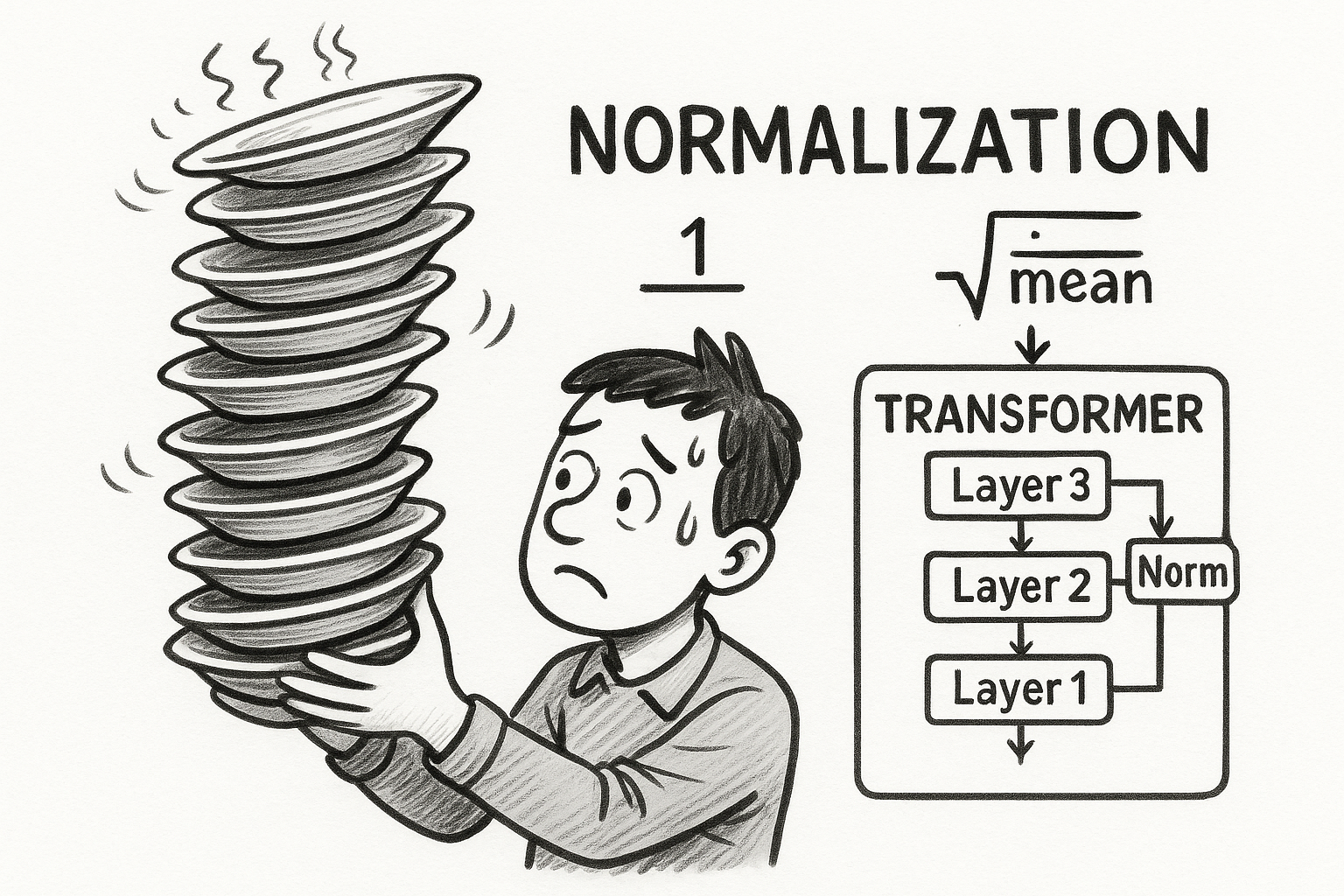
In this post, we’ll dive into the evolution of normalization in Transformer-based LLMs, from the trusty Layer Normalization (LayerNorm) to newer variants like RMSNorm, and even experimental tweaks. We’ll see why these norms are needed, how they differ, which major LLMs use them, and include some fun PyTorch code snippets (from scratch!) to illustrate how they work. Let’s start by understanding why normalization is so important for Transformers.
Why Do Transformers Need Normalization?
Training deep networks is notoriously tricky because as signals propagate through many layers, they can explode (become too large) or vanish (become too small). Normalization rescales the outputs of a layer to a friendlier range, which stabilizes and accelerates training. Think of it like a volume knob: each layer’s “voice” is adjusted to a reasonable volume so the next layer isn’t overwhelmed by shouting or straining to hear whispers. Normalization also helps maintain consistent gradients, so learning signals can flow from the output back to early layers without blowing up or petering out. In practice, normalization makes the optimization landscape smoother and training of very deep networks feasible.
Early on, Batch Normalization (BatchNorm) was the hero in computer vision networks, normalizing activations across a batch of examples. But for NLP and sequential models, BatchNorm isn’t ideal – sequence lengths vary and we often have small batch sizes or need to avoid cross-sample coupling. Transformers instead use Layer Normalization (LayerNorm), which normalizes across the hidden features within each sample (each position in the sequence). LayerNorm’s big advantage is that it doesn’t depend on batch statistics, so it works even with batch size 1 and doesn’t require global synchronization during distributed training. Nearly all modern LLMs rely on some form of LayerNorm or its variants to tame the internal covariate shifts – the fancy term for “distributions of activations changing as they pass through layers”.
In summary, normalization is critical for training stability in LLMs: it keeps each layer’s outputs well-behaved and comparable in scale. Without it, gradients could explode or vanish in deep Transformers, and training these 100+ layer behemoths would be immensely difficult. Now, let’s explore the specific normalization methods, starting with the classic LayerNorm.
LayerNorm – The Standard Normalization in Transformers
Layer Normalization was introduced by Ba et al. in 2016 as an alternative to BatchNorm for situations where batching isn’t as effective (like RNNs and Transformers). In a LayerNorm, for each individual sample and position, we take the vector of hidden units (of size d_model) and normalize it to have zero mean and unit variance. In other words, we compute:
μ = (1/d) Σ_i^d x_i, σ² = (1/d) Σ_i^d (x_i − μ)²
then output LayerNorm(x) = γ ⊙ (x - μ) / √(σ² + ε) + β. Here γ and β are learnable vectors the same size as x, representing a per-feature scale (gain) and shift (bias) applied after normalization. The tiny ε is just a safety net to avoid division by zero. Intuitively, LayerNorm ensures each layer’s output has a consistent distribution (zero-centered and not too spread out), but then allows the model to re-scale and re-shift each dimension via γ and β as needed for flexibility.
Why does this help? By normalizing, we remove the effect of differing magnitudes or means in the activations – the next layer sees inputs that are on a similar scale. This improves gradient flow (no layer gets stuck because its inputs are always too large or small) and makes training more efficient. Unlike BatchNorm, LayerNorm’s computation is independent for each sample, which means it works the same during training and inference, and it doesn’t matter how we batch or shuffle sequences. This property is crucial for LLMs which often generate one sequence at a time during inference.
In Transformers, Vaswani et al.’s original "Attention Is All You Need" paper incorporated LayerNorm in each sub-layer to stabilize the deep network. Every Transformer block has two sub-layers (the self-attention and the feed-forward network), each followed by a LayerNorm (plus the residual skip connection). This was shown in the paper as an “Add & Norm” step after each sub-layer. BERT, for example, uses LayerNorm extensively – after its attention output and after the intermediate feed-forward, as well as one final LayerNorm at the end of the encoder stack. With 12–24 layers, these normalizations are key to BERT’s training convergence.
Let’s implement a simple LayerNorm from scratch in PyTorch to see how it works:
import torch
import torch.nn as nn
class CustomLayerNorm(nn.Module):
def __init__(self, dim, eps=1e-5):
super().__init__()
# Learnable scale and bias, initialized to 1 and 0 respectively
self.gamma = nn.Parameter(torch.ones(dim))
self.beta = nn.Parameter(torch.zeros(dim))
self.eps = eps
def forward(self, x):
# Compute mean and variance across the last dimension (feature dim)
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False) # using population variance
# Normalize to zero mean, unit variance
x_norm = (x - mean) / torch.sqrt(var + self.eps)
# Scale and shift
return x_norm * self.gamma + self.beta
# Example usage:
batch_size, seq_len, hidden_dim = 2, 5, 10
x = torch.randn(batch_size, seq_len, hidden_dim)
layer_norm = CustomLayerNorm(hidden_dim)
y = layer_norm(x)
print("Output mean:", y.mean(dim=-1)) # should be ~0
print("Output std:", y.std(dim=-1, unbiased=False)) # should be ~1In the code above, CustomLayerNorm computes the mean and variance of each vector x (of size dim), then normalizes and applies a learned scale (gamma) and shift (beta). If you run this, you’ll find that each output vector y has mean approximately 0 and standard deviation 1 (aside from tiny numerical deviations). The learned parameters γ and β allow the model to undo or adjust the normalization for each feature if needed, but at initialization they start as γ = 1, β = 0 (so the layer outputs are initially truly zero-mean, unit-variance).
PyTorch’s built-in nn.LayerNorm does exactly this under the hood (in C++ for efficiency). For instance, we could replace our custom class with nn.LayerNorm(normalized_shape=hidden_dim) and get the same result. By default, PyTorch’s LayerNorm will create a γ (weight) and β (bias) vector of size normalized_shape, and apply the formula above for each sample.
BatchNorm vs LayerNorm: It’s worth noting why we don’t use BatchNorm in Transformers. BatchNorm normalizes across the batch, requiring meaningful batch statistics; it also introduces differences between training (using batch stats) and inference (using moving averaged stats). In language modeling, we often can’t afford large batch sizes (especially for very long sequences) and differences in sequence lengths or positions make batch-wise normalization less appropriate. LayerNorm, by normalizing per sample and per layer, avoids these issues. Moreover, in distributed training of huge models, BatchNorm would require syncing stats across devices – LayerNorm doesn’t need any of that, making it much easier to scale up. For these reasons, LayerNorm became the de facto standard normalization for Transformers and LLMs.
Post-LN vs Pre-LN Transformers
One wrinkle in using LayerNorm is where to apply it in a Transformer block. The original Transformer design (sometimes called Post-LayerNorm) places the LayerNorm after the sub-layer and its residual addition. In pseudocode, a post-LN block does: y = x + Sublayer(x); output = LayerNorm(y). However, later research found that for very deep Transformers, this placement can lead to training difficulties (gradients in early layers become very small). An alternative Pre-LayerNorm design normalizes before the sub-layer: y = Sublayer(LayerNorm(x)) + x (with sometimes an extra LayerNorm at the end of the block or end of the model). This Pre-LN setup lets gradients flow better back through the network, because the residual connection is unnormalized (an identity path) and the LayerNorm’s scale doesn’t directly attenuate the gradient from above.
Illustration of Post-LN vs Pre-LN Transformers. The left shows the original (Post-LN) Transformer block where each sub-layer’s output is added to the input then normalized (purple “Add & Norm”). The right shows a Pre-LN variant where normalization is applied to the input of the sub-layer instead. Pre-LN allows more direct gradient flow (the residual path is untouched by normalization), which helps when stacking many layers.
Empirically, Pre-LN Transformers tend to train more stably for deeper models. In fact, the official Transformer implementation was later updated to use Pre-LN by default for better performance on deep networks. Many modern LLMs adopted this. For example, OpenAI GPT-2 moved LayerNorm to the beginning of each sub-block (like a pre-activation ResNet) and also added a final LayerNorm after the last layer. This change was explicitly mentioned in the GPT-2 paper: “Layer normalization... was moved to the input of each sub-block, similar to a pre-activation residual network... and an additional layer normalization was added after the final self-attention block.”. This Pre-LN architecture was used in GPT-2 and GPT-3, enabling them to successfully train networks up to 48 or 96 layers deep. Google’s T5 (2019) encoder-decoder model likewise used a Pre-LN setup – their layers normalize the input before attention and feed-forward sub-layers (and T5’s normalization was a bit special, as we’ll see next).
Pre-LN does come with a caveat: because the residual connection isn’t normalized, the model’s representations can drift or “collapse” if not careful. In practice, this isn’t usually an issue with proper initialization and optimizer settings, but researchers have proposed clever tricks to get “the best of both worlds.” For instance, DeepNorm (Wang et al., 2022) modifies the Transformer equations by scaling the residuals by a constant factor α at each layer to counteract any distribution drift. According to the authors, DeepNorm’s approach “combines the good performance of Post-LN with the stable training of Pre-LN”, allowing them to stack an incredible 1000 Transformer layers without instability! We’ll talk more about DeepNorm later on. First, let’s discuss a popular alternative to LayerNorm that has taken the LLM world by storm: RMSNorm.
RMSNorm – Root Mean Square Normalization (Dropping the Mean)
If LayerNorm is about re-centering and re-scaling each layer’s activations, RMSNorm asks: do we really need the re-centering part? 😏 In RMSNorm, we skip subtracting the mean and only normalize by the vector’s magnitude (root mean square). Formally, RMSNorm of a vector is:
,
where is again a learnable scale vector (same shape as ). Notice the absence of — we don’t subtract the mean. We simply divide by its RMS, which is , and multiply by . There is typically no bias term in RMSNorm (no ), since without mean subtraction the output isn’t guaranteed to be zero-centered — adding a bias could arbitrarily shift it away from zero mean.
RMSNorm was first proposed by Zhang & Sennrich (2019). They hypothesized that LayerNorm’s mean normalization (“re-centering invariance”) wasn’t crucial for stable training, and only the scaling part (“re-scaling invariance”) mattered. By cutting out the mean subtraction and bias, RMSNorm saves some computation and is simpler. The original RMSNorm paper showed 7%–64% training speedups in certain RNN and Transformer models by using RMSNorm, with no loss in performance. In other words, they achieved comparable results to LayerNorm but faster – especially on hardware where LayerNorm’s two-pass computation (compute mean, then variance) was costly on memory bandwidth. RMSNorm provides the model a property called “rescaling invariance” – if the input is scaled by any factor, the output after RMSNorm is unchanged (aside from the learned scaling). This can act like an implicit learning-rate adaptation, potentially stabilizing training.
To illustrate RMSNorm, here’s a PyTorch implementation from scratch:
class CustomRMSNorm(nn.Module):
def __init__(self, dim, eps=1e-8):
super().__init__()
self.gamma = nn.Parameter(torch.ones(dim)) # scale only
self.eps = eps
def forward(self, x):
# Compute mean of squares (i.e., the mean square across last dimension)
rms = torch.sqrt((x * x).mean(dim=-1, keepdim=True) + self.eps)
# Divide x by RMS (so output has unit RMS), then scale by gamma
x_norm = x / rms * self.gamma
return x_norm
# Example usage:
x = torch.randn(batch_size, seq_len, hidden_dim)
rms_norm = CustomRMSNorm(hidden_dim)
y = rms_norm(x)
print("Output RMS:", torch.sqrt((y ** 2).mean(dim=-1))) # should be ~1 for each sample
print("Output mean:", y.mean(dim=-1)) # not necessarily 0!In this code, CustomRMSNorm computes the root mean square of the features and normalizes by that. We check that the output’s RMS is ~1, but the mean is not constrained (it can be non-zero). PyTorch now provides nn.RMSNorm in its toolkit as well, which similarly only has a weight parameter (scale) and no bias. The usage is straightforward:
layer_norm = nn.LayerNorm(hidden_dim)
rms_norm = nn.RMSNorm(hidden_dim)
out1 = layer_norm(x)
out2 = rms_norm(x)Both out1 and out2 will be normalized in scale, but only out1 is normalized in mean as well. If you print layer_norm.bias you’ll see a Parameter vector (the β), whereas rms_norm has none.
So, what’s the effect of dropping the mean? Proponents of RMSNorm noted that the mean might just be a redundant shift that the network could learn to handle. By removing it, we reduce computation and potentially avoid certain constraints. Indeed, the authors showed “re-centering has little impact on stabilizing training... and RMSNorm is similarly or more effective.” Many in the community initially adopted RMSNorm for the speed gains. For instance, the T5 model (2019) quietly used RMSNorm instead of LayerNorm (the paper didn’t shout about it, but the code did). By doing so, T5 likely benefited from a slight training speedup (on the order of 7–9% for Transformers as reported by the RMSNorm paper). Google’s mega-scale PaLM models (2022) continued this trend – PaLM’s architecture descended from T5 and also employed RMSNorm for its Transformer layers.
Meanwhile, DeepMind’s Gopher (280B-parameter LLM, 2022) provides a case study in why RMSNorm became attractive for very large LLMs. Gopher had 80 Transformer layers, and the researchers specifically chose RMSNorm over LayerNorm for normalization. The rationale was twofold: (1) both LN and RMSNorm don’t depend on batch size (unlike BatchNorm) which is important when you have to split training across many devices, and (2) RMSNorm was reported to improve training stability in deeper architectures. When scaling to dozens or hundreds of layers, even small differences in how gradients flow can matter. RMSNorm’s rescaling invariance might help keep gradients in a safe range even when the model is extremely deep. Meta AI also embraced RMSNorm in their open-source LLMs – most notably LLaMA (2023) and its successors. LLaMA’s architecture made a few key tweaks to the standard Transformer: it uses pre-normalization of inputs (Pre-LN style) with RMSNorm instead of LayerNorm. The designers noted that “LayerNorm stabilizes training but introduces additional overhead, which becomes substantial for deeper networks.” By using the simpler RMSNorm, they cut some overhead and got comparable results. And indeed, LLaMA showed that very large models (up to 65B parameters in LLaMA 1, and beyond in LLaMA 2/3) can train just fine with RMSNorm in place of LayerNorm. It has since become common for new LLMs to use RMSNorm (especially those influenced by LLaMA or T5 designs), whereas models following the GPT-3/GPT-4 lineage often use LayerNorm. Both techniques dominate modern Transformers – it’s either LN or RMSNorm in virtually all cases.
It’s not all roses for RMSNorm, though. By not centering the activations, RMSNorm outputs can have a non-zero mean that drifts over the layers. Recent analysis suggests this could pose an issue for quantization (when reducing model precision to 8-bit or 16-bit) because those methods work best when values are centered around 0. A 2025 study by Costello et al. found that in models like LLaMA, the activation means indeed wander as you go deeper (growing larger in later layers). LayerNorm, by construction, keeps the mean at 0, potentially giving it an advantage for numeric stability in low precision. Furthermore, improved implementations of LayerNorm have narrowed the speed gap. The same study showed that with optimized one-pass algorithms or fused kernels, LayerNorm can be just as fast as RMSNorm, and the historical performance gap was largely due to naive implementations. In their words: “LayerNorm is superior compared to RMSNorm, due to its stability and its compatibility with quantization... the performance gap... has closed to nothing.”. This has sparked some debate in the community. As of now, however, RMSNorm remains extremely popular because it has proven effective in practice for training huge models. For example, Meta’s LLaMA-2 and LLaMA-3 continue to use Pre-LN RMSNorm in each Transformer block. Many open models like StableLM and others built on LLaMA also inherit RMSNorm. On the other hand, OpenAI’s GPT-4 (whose details are less public) likely sticks with LayerNorm (following GPT-3’s design). We have effectively two schools in LLM architecture: “GPT-style” (Pre-LN LayerNorm) and “T5/LLaMA-style” (Pre-LN RMSNorm).
Summary of LN vs RMSNorm: Both serve to normalize layer activations for stable training. LayerNorm normalizes mean and variance, keeping outputs zero-centered, and has a learned scale and bias. RMSNorm normalizes the magnitude (RMS) only, keeping variance roughly 1 but allowing mean shifts, with only a learned scale. RMSNorm is a bit simpler and was historically faster; it’s been used in several state-of-the-art LLMs (T5, PaLM, Gopher, LLaMA, etc.) for efficiency and stability in very deep models. However, LayerNorm’s centering can be beneficial for numeric precision and perhaps for certain regulatory effects on the network. In practice, both techniques achieve similar performance on language tasks – the choice often comes down to architectural lineage or subtle training stability considerations.
Beyond Basic Norms: DeepNorm, NormFormer, and Other Innovations
The story of normalization in LLMs doesn’t end with choosing between LayerNorm and RMSNorm. As researchers push model sizes and depths to new extremes, they have proposed new normalization strategies or tweaks to get even better stability and performance.
-
DeepNorm (Scaling Transformers Deep) – When Microsoft researchers wanted to train Transformers with 1000 layers (for extremely deep networks), even Pre-LN wasn’t enough. They introduced DeepNorm, which modifies the residual connection itself. In DeepNorm, each Transformer sub-layer (attention or feed-forward) is scaled by a constant factor
βinside the residual, and the residual branch from below is scaled byαbefore adding. By carefully choosingαandβbased on the total number of layers, they ensured that the updates at each layer remain bounded and don’t blow up as depth increases. The net effect is that the model trains reliably even with 1000 layers (which is an order of magnitude deeper than previous networks). DeepNorm was shown to combine “the best of two worlds, i.e., good performance of Post-LN and stable training of Pre-LN”. Practically, you can think of DeepNorm as a clever re-weighting: it amplifies the residual (skip connection) slightly and dampens the layer transformation output such that early layers don’t get drowned out by the accumulation of many residual additions. Some large-scale models have started to incorporate this kind of initialization and residual scaling (for example, GLM-130B from Tsinghua University mentions using DeepNorm in its architecture). If you ever see Transformer code with something likeoutput = alpha * x + sublayer(x) * beta, that’s DeepNorm at work. It’s a more behind-the-scenes technique compared to LayerNorm/RMSNorm (which are explicit layers), but it’s part of the normalization toolkit for ultra-deep models. -
NormFormer (Extra Norms for Better Training) – Facebook (Meta) researchers in 2021 asked: what if we just add more normalization inside each Transformer block? The result was NormFormer, which introduces three additional normalization steps in each layer. Specifically, NormFormer applies a LayerNorm right after the self-attention output (before adding the residual), does a per-head scaling of the attention outputs (learning a scalar for each attention head’s output vector), and also adds a LayerNorm after the first linear layer in the feed-forward network. These changes are minimal in terms of compute (+0.4% parameters, negligible runtime cost), but they showed notable improvements: training converged faster and to a lower perplexity, and downstream tasks like GLUE got a small boost. For example, a 1.3B parameter transformer reached the same perplexity 24% faster with NormFormer, and fine-tuned GLUE scores improved ~1.9%. NormFormer basically over-normalizes: rather than just one Pre-LN at the start of the block, it normalizes at multiple points to keep the activations in-check throughout the sub-layer computations. While NormFormer isn’t yet a standard in published LLM architectures, it’s an idea that could be adopted in future models to squeeze out more training efficiency. It shows that even after years of Transformers, we’re still finding new tricks with where and how to normalize for optimal results.
-
ScaleNorm and Others – Another variant introduced around 2019 is ScaleNorm, proposed in “Transformers without Tears”. ScaleNorm simplifies things even further: it normalizes by the norm of the vector, and uses a single learned scalar parameter for scaling. In formula, ScaleNorm does
x * |c| / |x|(where|c|is a learned constant,|x|is the vector norm). Essentially, it forces the whole vector to a certain length. This was reported to speed up training and was paired with other tricks like “FixNorm” in that paper. However, ScaleNorm hasn’t seen wide adoption in major LLMs – possibly because RMSNorm offered a similar speed benefit without completely discarding component-wise flexibility (ScaleNorm uses one global scale for all features, whereas RMSNorm still has elementwise learnedγ). It’s an interesting idea and might lurk in some research implementations, but if you’re reading a model’s code and see no mean subtraction and just a scalar scale, that could be ScaleNorm. -
QK Norm (Attention-specific normalization) – Beyond normalizing the layer outputs, some research has looked at normalizing parts of the attention mechanism itself. For instance, Query-Key Normalization (QKNorm) normalizes the query and key vectors in self-attention to have unit norm, ostensibly to stabilize the dot-product magnitude. By doing so, it prevents extreme variability in attention scores from different heads or tokens. There’s also been exploration of normalizing attention weights or using softmax variants that implicitly normalize. These are more specialized and not standard in most LLMs, but they reflect the ongoing tinkering in this space to make Transformers more robust.
-
No Norm at All? An intriguing recent finding is that, at least for already-trained models, LayerNorm might not be as critical as we think for inference. A 2023 study “Transformers Don’t Need LayerNorm at Inference Time” showed that one can remove all LayerNorm layers from a trained GPT-2 model by folding their effect into neighboring linear layers or doing a light finetuning, with only a tiny hit to performance (increase of 0.03 in cross-entropy loss for GPT-2 XL). This suggests that once the model is trained and the weights have adapted, the normalization is not playing a major role in the final function – it was mainly a crutch to get it trained. The authors argue that removing LayerNorm simplifies interpretability (since LayerNorm’s scaling is a weird non-linear interaction across neurons). They successfully fine-tuned GPT-2 models to be LN-free at inference, and the models worked almost the same. However, note that training a transformer from scratch without any normalization is still extremely challenging (if not impossible) for deep networks – the study only removed norms after training. So, while we might not need LayerNorm at inference, we absolutely rely on some normalization during training of LLMs. Perhaps in the future we’ll discover architectures or initialization schemes that truly don’t need normalization at all (there’s ongoing research into normalization-free Transformers), but for now, normalization remains a core part of stable LLM training.
Conclusion
Normalization has been a unsung hero in the rise of LLMs. From the early days of LayerNorm enabling the first Transformers and BERT to train deeply, to the introduction of RMSNorm which simplified and sped-up training for massive models, and further to specialized techniques like DeepNorm that push depth limits – the evolution of normalization methods has gone hand-in-hand with the scaling of language models. We saw that LayerNorm vs RMSNorm became a fork in the road for different model families, each with its pros and cons. LayerNorm centers activations (helpful for quantization and perhaps interpretability) but RMSNorm showed that sometimes you can drop the centering and still be fine, gaining a bit of efficiency. It’s fascinating that something as simple as “subtract the mean or not” can make a measurable difference in training a 100-billion-parameter model!
For practitioners, the good news is that frameworks like PyTorch provide these normalization layers out-of-the-box – you don’t have to implement them from scratch (we did here just to illustrate). Use nn.LayerNorm for traditional layer normalization (PyTorch will handle the vectorized mean/var computation efficiently), or nn.RMSNorm (available in recent PyTorch versions) for the mean-free variant. Both are easy to drop into your Transformer code. And if you’re experimenting with custom architectures, keep an eye on research – ideas like adding extra norms (NormFormer) or scaling residuals (DeepNorm) might be beneficial tweaks.
To keep things fun: one can think of normalization layers in an LLM as team coaches ensuring each layer of neurons “plays nice” with others – no one layer hogs the spotlight with gigantic values, and none stay silent. As models grow ever more complex, these coaches have to get smarter (hence variants and strategies emerge). There’s even discussion about whether we needed some of these norms as much as we thought, evidenced by post-training norm removal experiments. But until we crack the code for completely normalization-free training, techniques like LayerNorm and RMSNorm will remain essential ingredients in the recipe for training stable, state-of-the-art LLMs.
References: The insights and quotes in this post come from various papers and articles on normalization in deep learning and Transformers, including the original LayerNorm paper by Ba et al. (2016), the Transformer and GPT-2 papers, the RMSNorm introduction and usage in LLMs like Gopher and LLaMA, as well as analysis by researchers like Sebastian Raschka and Tom Costello on the impact of these techniques. These sources are cited throughout (in the format 【citation†lines】) for those who want to read further into each development. Happy training, and may your gradients be ever smooth!