April 30, 2024/2 min read
LLaVA: Large Multimodal Model
LLaVA is a multimodal large language model that has a vision encoder and a language encoder. It is trained on a large-scale multimodal dataset and can generate text conditioned on images
LLaVA stands for Large Language and Vision Assistant
LLaVA is an end-to-end trained LMM (Large Multimodal Model) that combines a pre-trained vision encoder and an LLM (large language model) to generate text conditioned on images.
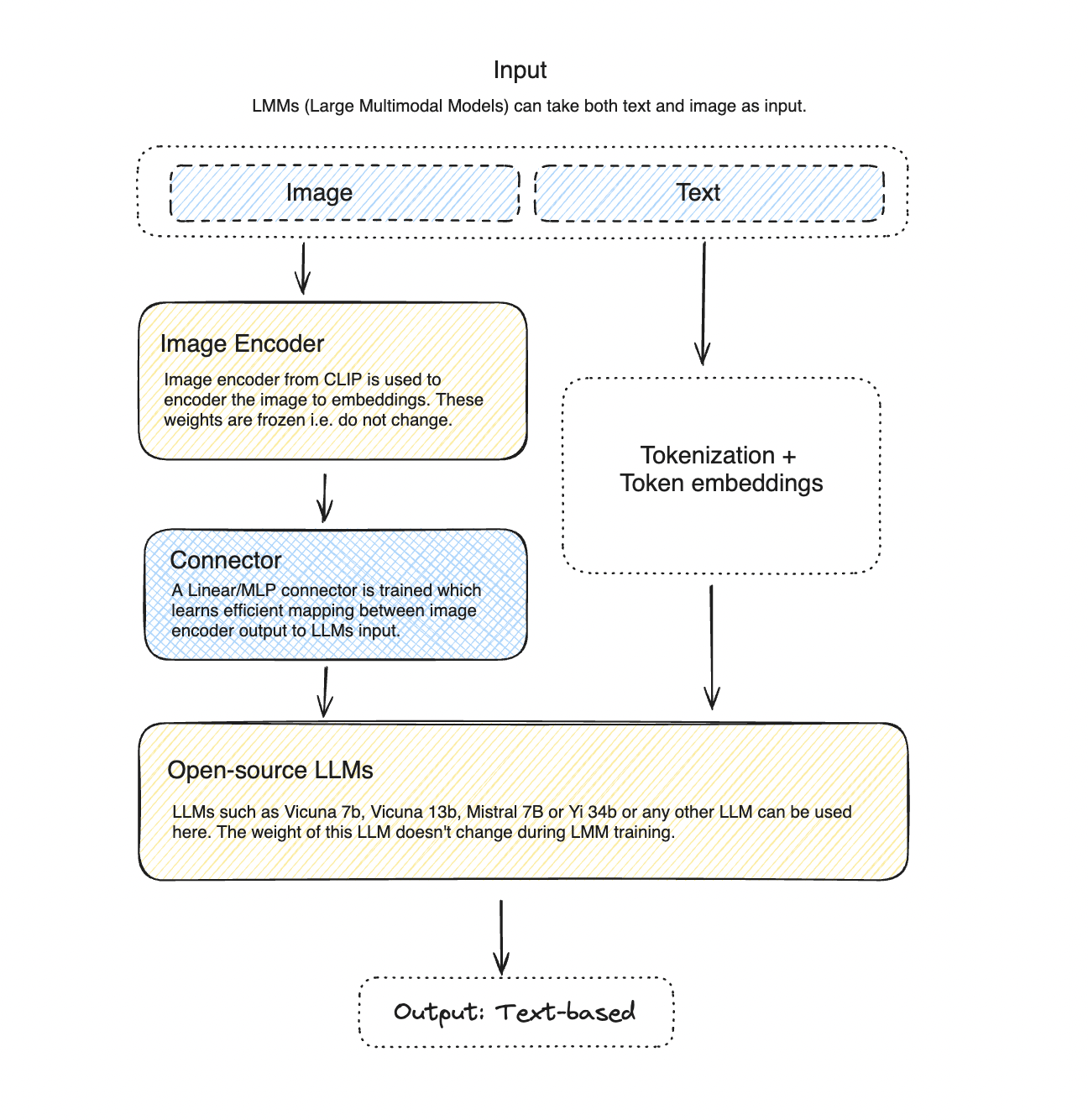
Figure 1: LLaVA Architecture - it can take both text and image as input and processes these inputs to generate a text-based output. The weights for both image encoder and LLM are frozen and only the connector weights are trained during the training process.
Architecture
As the name suggests an LMM, can take multiple modalities as inputs in this case both text and image and then processes these inputs to generate a text-based output.
The architecture is roughly a vision encoder that is used to encode the image and the output of the vision encoder is then then passed through an connector (which is generally an MLP) to generate image embeddings. These image embeddings are then concatenated with the token embeddings and passed through the language model to generate the output text that is conditioned on the both image and text input.
The vision encoder and the language model are pre-trained and only the connector weights are trained during an LMM training process.
Training
The parameters of the vision encoder and the language model are frozen (do not change during the training process) and only the connector weights are trained during the training process. The model is trained on a large-scale multimodal dataset that consists of images and text.
LLaVA 1.5
LLaVa [1] connects pre-trained CLIP ViT-L/14 [3] visual encoder and large language model Vicuna, using a simple projection matrix. We consider a two-stage instruction-tuning procedure.
LLaVA NeXT
LLaVA NeXT [2] (v1.6) makes simple modifications to original LLaVA (v1.5), namely, using CLIP-ViT-L-336px with an MLP projection and adding academic-task-oriented VQA data with simple response formatting prompts. These changes help establish stronger baselines that achieve state-of-the-art across 11 benchmarks.
The LLaVA v1.6 has multiple variants. All of these variants use the CLIP-ViT-L-336px visual encoder but differ in the language model used. Listed below are the different variants of LLaVA v1.6:
- LLaVA-v1.6-mistral-7b - Uses the Mistral-7B language model
- LLaVA-v1.6-vicuna-7b - Uses the Vicuna-7B language model
- LLaVA-v1.6-vicuna-13b - Uses the Vicuna-13B language model
- LLaVA-v1.6-34b - Uses the Nous-Hermes-2-Yi-34B language model
references
- Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee. Visual Instruction Tuning. arXiv:2304.08485
- Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee. Improved Baselines with Visual Instruction Tuning. arXiv:2310.03744
- Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. arXiv:2103.00020