RAG Triad - Evaluating Quality of Response from LLMs
Table of Contents
- Introduction
- Rag Triad
- Context Relevance
- Groundedness
- Answer Relevance
1. Introduction
RAG is the standard architecture for providing LLMs with the relevant context to reduce hallucinations. It has been shown to improve performance on a variety of tasks. In this blog post, we will look at the RAG triad and how it can be used to evaluate the quality of response from LLMs.
Why is RAG needed?
Autoregressive LLMs such as GPT-3 have been shown to generate high-quality text. However, they often suffer from hallucinations, that is they generate text that is factually incorrect or misleading. This is because autoregressive models generate text based on the probability distribution of the next word given the previous words, without considering any particular context.
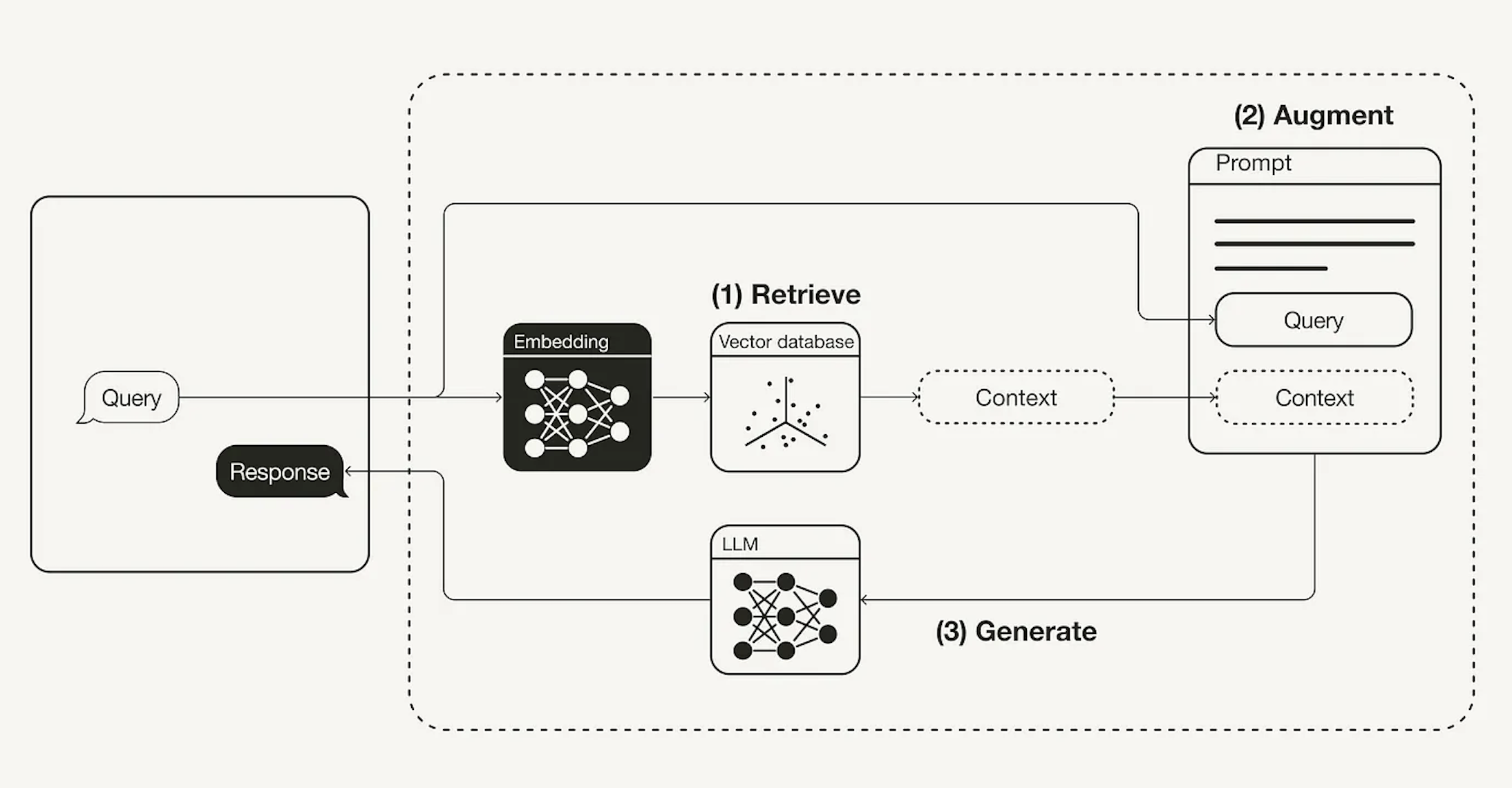
RAG addresses this issue by providing the LLM with the relevant context. It does this by retrieving relevant passages from a large corpus of text and using them as input to the LLM. This allows the LLM to generate text that is grounded in the context provided by the retrieved passages.
However, even RAG can sometimes generate text that is factually incorrect or misleading. This is why it is important to evaluate the quality of the response generated by the LLM.
Components of RAG
The three components that are there are in RAG are
- Query - The question or prompt provided to the RAG pipeline
- Context - The relevant content retrieved by the RAG process
- Response - The text generated by the LLM in response to the query and context
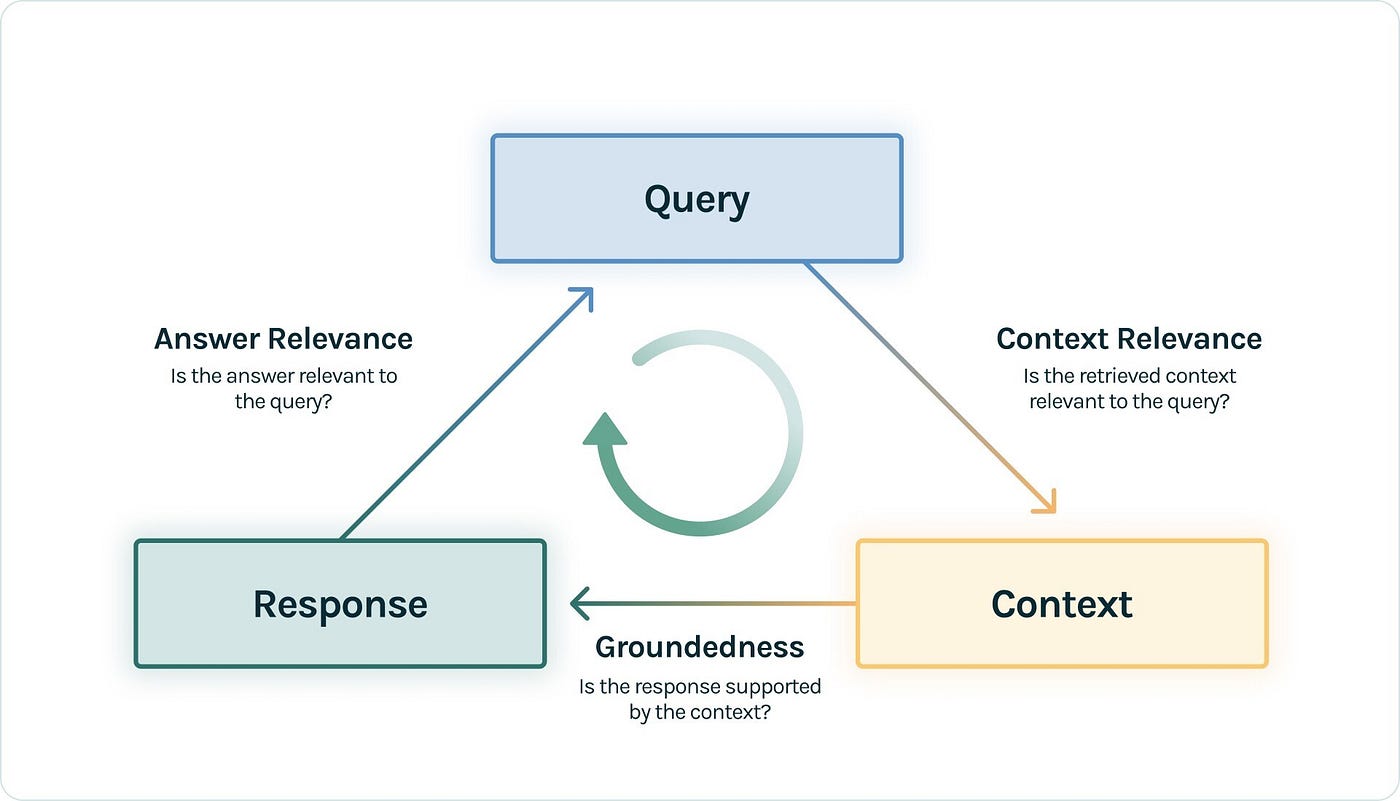
2. The RAG triad
The RAG triad consists of three different pairwise evaluations that can be used to evaluate the quality of the response generated by the LLM.
2.1. Context Relevance
(Query <-> Context) measures how well the context retrieved by RAG is relevant to the query. A high score on this evaluation indicates that the context is relevant to the query and provides the LLM with the necessary information to generate a high-quality response.
2.2. Groundedness
(Context <-> Response) measures how well the response generated by the LLM is grounded in the context provided by RAG. A high score on this evaluation indicates that the response is grounded in the context and is factually correct.
2.3. Answer Relevance
(Query <-> Response) measures how well the response generated by the LLM is relevant to the query. A high score on this evaluation indicates that the response is relevant to the query and answers the question asked.
References
- Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401