Multi Query Attention
The Transformers model [Vaswani et al., 2017][2] has emerged as a popular alternative to recurrent sequence models. Transformer relies on attention layers to communicate information between and across sequences. One major challenge with Transformer is the speed of incremental inference. As we will discuss, the speed of incremental Transformer inference on modern computing hardware is limited by the memory bandwidth necessary to reload the large "keys" and "values" tensors which encode the state of the attention layers.
Multi-Query Attention by introduced in (Shazeer, 2019)[1] in a paper titled "Fast Decoding Transfomer: One Write-Head is All You Need". In the following sections, we will review the multi-head-attention layers used by original Transformer, provide a performance analysis, and compare the novel architectural variation (multi-query attention) which greatly improves inference speed with only minor quality degradation.
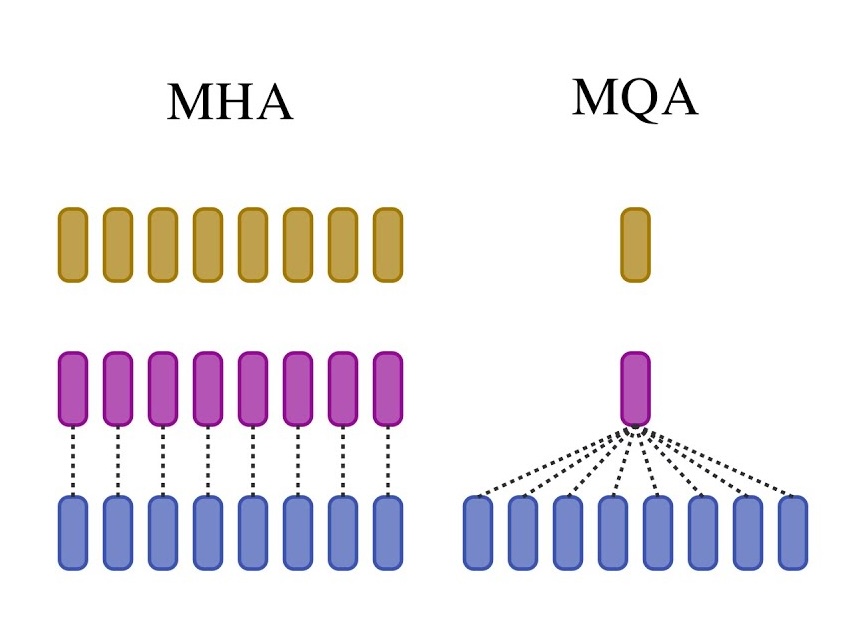
Figure 1: Multi-Head Attention (MHA) has H Queries, Keys and Values. Multi-Query Attention (MQA) share single Key and Value heads across all Query heads.
Multi-Head Attention
The Transformer sequence-to-sequence model [Vaswani et al., 2017][2] uses h different attention heads in parallel, which was called the "Multi-Head Attention" (MHA). The query vectors of the different attention heads are linear projections of the input sequence, and the key and value vectors are linear projections of the input sequence. The attention mechanism is applied to each head independently, and the results are concatenated and linearly transformed to produce the output of the attention layer. Each 'head' in MHA learns a different aspect of the data, and their outputs are concatenated and linearly transformed into the final output.
Multi-Head Attention (Vanilla)
In a standard setup, attention scores are computed for all pairs of input positions in a single batch, which is computationally intensive as it involves matrix multiplications between large tensors.
Multi-Head Attention (Batched)
Optimization: This approach modifies the MHA computation by batching the queries and/or keys and values to process them in smaller groups rather than all at once. This can help manage memory usage more efficiently and speed up computations by taking advantage of batch processing capabilities of modern hardware.
Use Case: Particularly useful in scenarios where the sequences are very long or when the hardware is limited in terms of memory capacity.
Multi-Head Attention (Incremental)
Optimization: Incremental MHA is designed for scenarios like autoregressive decoding, where one token is generated at a time, and the subsequent token's attention computation depends on the previous tokens. Instead of recomputing attention scores for the entire sequence at each step, incremental MHA updates the attention scores by adding the latest token's computations to previously computed values.
Efficiency: This method reduces the amount of computation needed at each decoding step, as it reuses previous calculations and adds only the necessary incremental part corresponding to the new token. It's particularly effective in reducing latency during decoding.
Both "Multi-Head Attention Batched" and "Multi-Head Attention Incremental" are optimizations of the standard MHA designed to handle specific computational challenges. The batched method optimizes memory and computational efficiency for processing large batches or long sequences, while the incremental method optimizes decoding tasks by incrementally updating attention scores, thereby reducing repetitive computation and improving response time.
These modifications are crucial for deploying Transformer models in environments where computational resources are a constraint or where rapid response is critical.
References
- Noam Shazeer. Fast Transformer Decoding: One Write-Head is All You Need. arXiv:1911.02150
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention is All You Need. arXiv:1706.03762